
Often when I am walking/driving, I like looking at details of my surroundings. I like looking at waves on the St Lawrence River and I definitely want to try to explain the wave patterns better. My M.Sc. supervisor might have some papers to help understand that better (examples or just a link), which I will hopefully get to in the not-too-distant future. One thing that really bothers a lot of people is a traffic jam. I had some thoughts on this topic and am getting around to writing about it. I will try tailoring this post to address a wide audience. There should be a follow-up article exploring some more mathematical details.
There are quite a few papers (including some work by an academic “great-uncle” (PhD supervisor’s postdoctoral co-supervisor) of mine, Nigel Goldenfeld) studying traffic and the origins of traffic jams. Do traffic jams occur as an intrinsic part of the system (cars interacting with each other on a network of roads)? Or is it because of individual behaviours which give rise to these problems? You might think the latter is more reasonable, but in certain cases very different behaviours of the constituent parts (how drivers drive their vehicles) can result in the same behaviour of the system (traffic jams), if some very general rules are followed.
Let’s start with a one-lane road:

A “typical” car is 4 metres long (in the diagram 

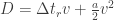
We can take the reaction time, 




The least space a single car takes up when trying to be safe is about:

Correspondingly, the maximum density of cars is reciprocal of the above relation so:

Taking 
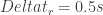


Density (cars/m) vs Speed (m/s)
A car takes up effectively less space at lower speeds when trying to be safe according to this model, so highways being slowed down to surrounding roads at high traffic density (many cars on a single road at the same time) is intuitive. Let us extend this by looking at the flow rate of cars, 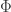


Flow rate (cars/sec) vs velocity (m/sec)
Looking at some integer values, there’s a peak around 6 m/sec:
| phi (cars/sec) | v (m/sec) | |
|---|---|---|
| 0 | 0.000000 | 0.0 |
| 1 | 0.370370 | 2.0 |
| 2 | 0.526316 | 4.0 |
| 3 | 0.566038 | 6.0 |
| 4 | 0.555556 | 8.0 |
| 5 | 0.526316 | 10.0 |
| 6 | 0.491803 | 12.0 |
| 7 | 0.457516 | 14.0 |
| 8 | 0.425532 | 16.0 |
| 9 | 0.396476 | 18.0 |
| 10 | 0.370370 | 20.0 |
(Note that this is not exact, but I’m using this method to illustrate that although rigor and exactness in calculations and quantitative methods is nice and often important, in a lot of cases, rigor and exactness are difficult to obtain because of too many unknowns. In such cases, resorting to something simple to get a sense of what is being studied can help.)
Experimenting with different parameters, I often got peak flow rates around 5-10 m/sec which is 18-36 km/h or 10-20 mph. With the current parameters, a peak occurring at a little over 20 km/h suggests. (On a side note, I am wondering if this gives some intuition into one factor as to what suitable speed limits should be — at typical traffic levels, what is a safe speed on that road?) Interestingly, there is a conflict between how fast an individual travels through a region and how all vehicles do. On a nearly empty road, you can choose to drive however fast you want (being mindful of the speed limit). Eventually as the density of cars increases, the speed at which they can safely travel decreases. This results in the maximum flow of cars on the road (the number of car passing a fixed decreasing). This corresponds with the intuition that traffic jams occur at high traffic volumes but not at low ones (unless there’s construction).
The above reasoning is qualitative, but can help some one analysing a problem with giving them an intuition. In a future post, let’s see how this model performs under perturbations. Done, the next analysis will be appropriate for an upper year undergraduate student (though younger students with the appropriate calculus skills should be able to follow the arguments as well). That being said, be cautious of this particular model because it was only conceived in a thought experiment and was highly idealized (nothing was even considered about network effects — because real traffic happens in a “grid” of multi-lane roads with various signage affecting the traffic flow). When doing mathematics, that approach can be sufficient, but not when engaging in empirical empirical discipline like the natural sciences (e.g., physics, chemistry, biology) or social sciences (e.g., economics or politics).
